

By Henrique Fingler, Chris Sosa, Zhiming Shen, and Nayan Lad,
The Single-Model Efficiency Challenge
Following our previous analysis of mixed AI workloads, we turn our attention to a more fundamental question: How much GPU compute and memory do individual models actually need? In this blog, we examine the granular resource requirements of a single model to understand the true cost of GPU over-provisioning.
Many popular models are small and powerful, offering comparable performance and not requiring top-of-the-line hardware, or even mid-level hardware. For example, DeepSeek-R1 distilled models demonstrate that advanced reasoning capabilities can be compressed into efficient packages: DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, and DeepSeek-R1-Distill-Qwen-14B deliver performance comparable to OpenAI's o1-mini. Yet, these capable models routinely receive full GPU allocations, resulting in massive resource waste and cost inefficiency.
Additionally, most downloaded models on huggingface.co are much smaller than the LLMs we often read about :

For such models, which is the ideal hardware (GPU, TPU) to run them on? How cost-efficient will your choice be? Let’s do a case study of LLaMa 3.1 8B. The following evaluation was done on a local Kubernetes cluster running in a VM provided by Hot Aisle with an AMD MI300x. Check the end of this post for a sneak peek at HotAisle’s incredible terminal UI!
We chose an AMD GPU because Exostellar’s GPU Optimizer (formerly software-defined GPUs -SDG) supports compute and memory slicing: we can define a fraction of a GPU for a pod using Kubernetes-style units. For example, you could add these labels to your pod:
sdg.exostellar.io/vendor: "amd"
sdg.exostellar.io/memory: "4Gi"
sdg.exostellar.io/memoryLimit: "20Gi"
sdg.exostellar.io/compute: "100m"
sdg.exostellar.io/computeLimit: "500m"
sdg.exostellar.io/count: "1"
GPU Optimizer labels enabled precise resource allocation. compute and computeLimit are expressed in millis, similar to CPU request and limit (e.g. 1000m == 100% compute) . Similarly, memory and memoryLimit can be used to control GPU memory request and limit.
Experimental Design and Setup
Building on our established methodology with AMD MI300x and Exostellar GPU Optimizer, we conducted a comprehensive performance analysis of Llama 3.1 8B using vLLM. The MI300x's superior memory bandwidth (5.3TB/s vs H100's 2-3TB/s) and 192GB HBM3 capacity make it ideal for studying fractional GPU allocation patterns.
Test Configuration:
- Hardware: AMD MI300x (304 compute units, 191GB memory)
- Model: meta-llama/Llama-3.1-8B via vLLM
- Infrastructure: Kubernetes cluster with Exostellar GPU Optimizer
- Variables: Compute units and batch sizes
This granular control contrasts sharply with Nvidia MIG's fixed partitioning limitations and time-slicing's performance unpredictability. These labels are exactly the capacity of a whole MI300x. We evaluate throughput and request latency for different “batch sizes” (the max_num_seqs parameter to vLLM, which isn’t exactly batch size, but is analogous) and with different numbers of compute units: 10%, 25%, 50% and 100% of the GPU and powers of two CUs. For easier interpretation of the results, instead of presenting compute resources as a percentage number, we show actual CUs that are allocated to the pod.
Performance Analysis and Resource Pattern Insights
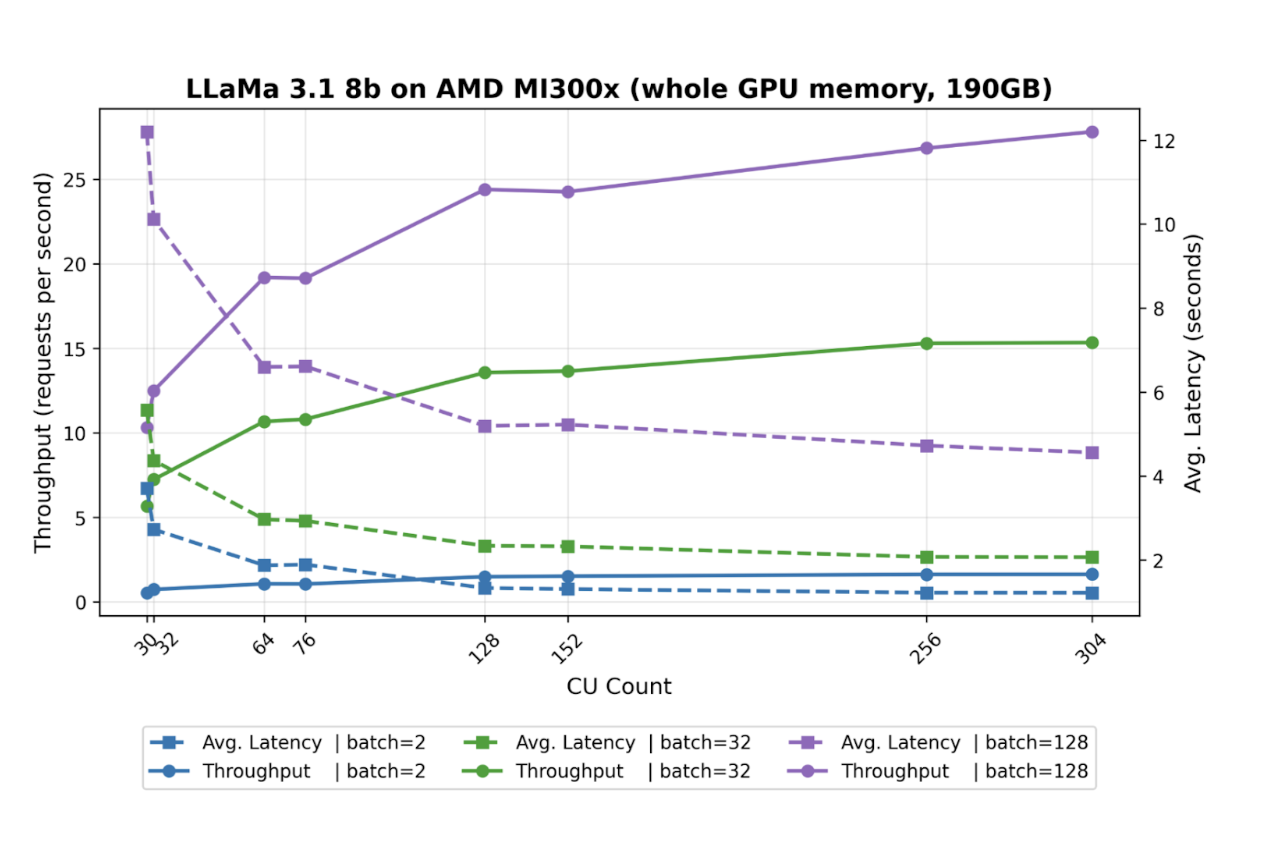
Compute Unit Efficiency Curves
Our throughput measurements reveal critical insights about GPU resource utilization patterns and the wildly different throughput values that we found point to a common pain point: GPU inefficiency. If a certain model only needs a certain number of requests per second, why should it get an entire GPU?
Batch Size 32 Performance:
- 32 CUs: 7.23 requests/second
- 64 CUs: 10.6 requests/second (47% increase for 100% more CUs)
- 128 CUs: 13.5 requests/second (27% increase for 100% more CUs)
The diminishing returns pattern indicates significant compute underutilization as resources scale. This non-linear scaling behavior directly contradicts the common practice of allocating entire GPUs to single models.
Power-of-Two Performance Anomalies
A particularly interesting finding emerged around compute unit alignment:
- 30 CUs: 5.6 requests/second
- 32 CUs: 7.2 requests/second (27% improvement)
- 64 CUs: 10.7 requests/second
- 76 CUs: 10.8 requests/second (<1% improvement)
This suggests hardware-level optimizations favoring power-of-two CU allocations, similar to memory alignment principles in traditional computing. In Figure 1, we only considered changing the CU count, but not the amount of memory the GPU Optimizer has. We found that the minimum memory required to support this model is 60GB. Below, we present the same benchmark, but with the GPU Optimizer memory size set to 60GB.
Memory Threshold and Patterns
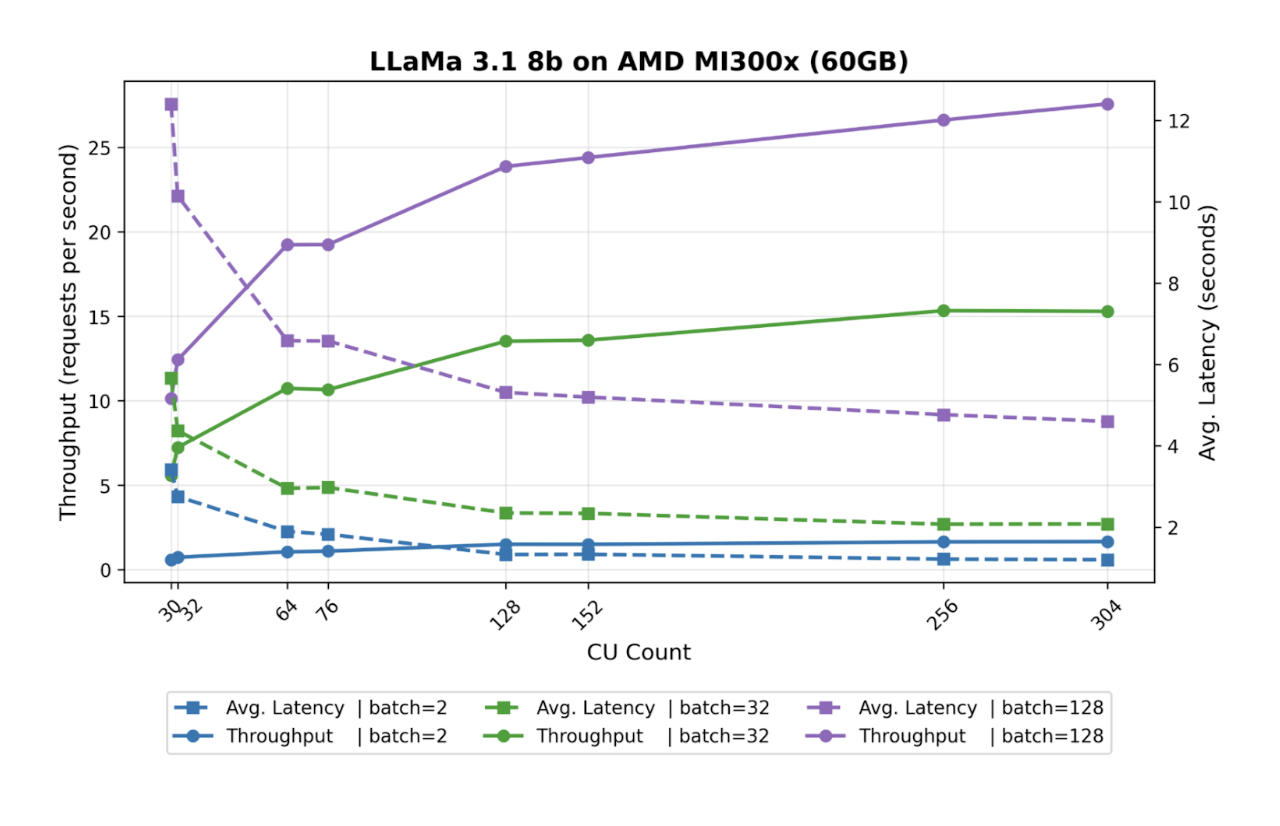
Our memory analysis revealed that Llama 3.1 8B requires a minimum of 60GB for stable operation. Testing with precisely 60GB versus the full 191GB available showed negligible performance differences:
Performance Variance Analysis:
- Range: -0.62% to +1.37%
- Average difference: 0.0324 requests/second
- Statistical significance: Negligible
This finding reinforces that memory over-provisioning beyond model requirements provides no performance benefit while consuming valuable resources that could support additional workloads.
Multi-Tenancy Performance Characteristics
To understand GPU Optimizer's multi-tenancy capabilities, we deployed two identical Llama 3.1 8B instances sharing a single GPU, each allocated roughly half the available compute units.

Multi-Tenancy Results:
- Individual model performance: 13% degradation due to memory bandwidth sharing
- Combined throughput: 41.4 requests/second (vs 20.7 for single instance)
- Overall utilization: Nearly 200% improvement
The modest per-instance performance penalty is more than offset by the dramatic increase in total GPU utilization, demonstrating GPU Optimizer's effectiveness for multi-tenant scenarios.
It’s worth noting, though, that the data for sharing vllms shown in the graph (red bars) are the average between the two instances so, for example, for batch size of 128, each vllm is seeing a throughput of 10.7, a 13% drop relative to the same vllm running alone on the GPU, without other vllms sharing the GPU, but the overall throughput of the GPU is 41.4 requests per second, as there are two vllms running.
Resource Utilization Patterns in Production
Memory vs. Compute Bound Classification
Our analysis extends beyond Llama 3.1 8B to broader workload classification patterns observed in production environments:
Memory-Bound Inference Patterns:
- Autoregressive token generation phases
- Large context window processing (32K+ tokens)
- Multi-modal model inference with high-resolution inputs
- RAG applications with extensive vector database lookups
Compute-Bound Inference Patterns:
- Prompt processing phases (parallelizable)
- Real-time vision model inference
- Embedding generation tasks
- Reasoning model chain-of-thought processing
Understanding these patterns enables intelligent resource allocation that matches workload characteristics to available hardware resources.
Economic Impact: Using Exostellar Smart Right-sizing
The performance improvements translate directly to infrastructure cost savings:
GPU Utilization Efficiency:
- Traditional allocation: 1 model = 1 GPU
- Optimized allocation: 2-3 models per GPU with minimal performance degradation
- Cost reduction: 50-65% fewer GPUs needed for equivalent throughput
Real-World Deployment Scenarios:
- Development and testing environments: 4-5 models per GPU
- Production serving: 2-3 models per GPU with SLA guarantees
- Batch processing: 6-8 models per GPU for non-latency-sensitive workloads
Exostellar Smart Right-sizing Strategy
Implementing Exostellar's vLLM rightsizing profiles enables automatic resource optimization:
- Model profiling: Analyze memory and compute requirements during initialization
- SLA-based allocation: Match resources to latency and throughput requirements
- Dynamic scaling: Adjust resources based on real-time demand patterns
- Multi-tenancy optimization: Co-locate compatible workloads for maximum efficiency
Future Implications: The Path Forward
Emerging Workload Patterns
As AI applications evolve toward agentic architectures and multi-model workflows, the need for intelligent resource orchestration becomes more critical:
- Agent-based systems: Multiple specialized models working in concert
- Multi-modal applications: Vision, language, and audio models in unified pipelines
- Reasoning chains: Sequential model invocation with varying resource requirements
Infrastructure Evolution
The transition from monolithic GPU allocation to intelligent orchestration represents a fundamental shift in AI infrastructure design:
- From static to dynamic: Resource allocation adapts to workload demands
- From isolated to shared: Multiple workloads coexist efficiently
- From wasteful to optimized: Resources match actual requirements
Conclusion: Intelligent Orchestration as Competitive Advantage
Our analysis demonstrates that the future of AI infrastructure lies not in acquiring more GPUs, but in using existing ones more intelligently. The 47% performance improvement when doubling compute units from 32 to 64 CUs, combined with the negligible impact of memory over-provisioning, clearly indicates that traditional GPU allocation strategies are fundamentally flawed.
Organizations implementing intelligent resource orchestration can achieve:
- 50-65% reduction in GPU requirements for equivalent performance
- 2-3x improvement in resource utilization through informed multi-tenancy
- Predictable performance isolation without the rigidity of hardware partitioning
The era of "one model, one GPU" is ending. As models become more capable while remaining computationally efficient, the competitive advantage shifts to organizations that can extract maximum value from their existing infrastructure through intelligent orchestration.
Ready to optimize your AI infrastructure? Discover how Exostellar GPU Optimizer can transform your GPU utilization at exostellar.ai/contact.
Hot Aisle Shoutout
We thank Hot Aisle for providing us a VM with an MI300x. Check out their terminal UI, completely compatible with a terminal! All you need to do is access ssh admin.hotaisle.app and there you can even access the VM’s serial console!
Free Trial
For details or to start a trial, visit exostellar.ai/aim-free-trial







