
1. Introduction
Cloud computing promised infinite scalability, elastic infrastructure, and a future free of wasteful over-provisioning. But the reality is more complicated and far more expensive.
Today, cloud cost is one of the top concerns for engineering and finance teams. Despite sophisticated autoscaling tools and resource-aware schedulers, most cloud environments still suffer from a fundamental problem: they don't adapt well to changing workloads.
This blog post takes a deep look at why that is, and what can be done about it. We will walk through the most widely used resource optimization strategies, and introduce a new paradigm:
- Bin-packing, which aims to reduce idle resources by arranging workloads efficiently.
- Workload right-sizing and over-subscription, which attempt to reduce internal waste through smarter provisioning.
- Dynamic node-level right-sizing with Exostellar Workload Optimizer WO, a mechanism that we introduced for making virtual machines as elastic as the workloads they run.
Each solution addresses a different layer of the problem. We'll explain how they work, where they fall short, and how we can enable truly elastic cloud infrastructure.
2. The Cloud's Hidden Cost: Resource Fragmentation
Cloud computing has revolutionized how modern applications are built and scaled. It offers on-demand access to infrastructure, elastic scalability, and a pay-as-you-go model that aims to eliminate waste. However, in practice, cloud cost has become one of the top concerns for organizations today.
The 2025 Flexera State of the Cloud Report found that more than 80% of enterprises rank cloud cost management and optimization as the number one priority, with more than one-fourth of cloud spend being wasted on idle resources. As businesses migrate more of their operations to the cloud, they come to realize that inefficient resource usage is not just a technical debt, but also a financial challenge.
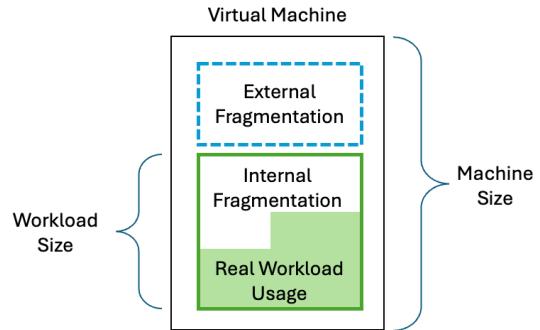
At the core of this problem is resource fragmentation: a mismatch between provisioned infrastructure and actual workload demand. This fragmentation takes two primary forms:
2.1 External Fragmentation: Unallocated Capacity at the Node Level
External fragmentation happens when allocated cloud VMs have leftover resources that no workloads can use. For example:
- A virtual machine might have 4 vCPUs, but only 2 vCPUs are allocated, while all pending workloads are asking for more than 2 vCPUs.
- A node has a lot of memory left, but all CPUs are allocated, preventing any other workloads from running on it.
The result is idle capacity that still incurs full cost.
2.2 Internal Fragmentation: Over-provisioned Workloads
On the flip side, internal fragmentation refers to resources that are allocated to workloads but are not fully utilized. This is especially common in autoscaled environments:
- Applications often request more CPU or memory than they actually need, just to be safe.
- Workloads with bursty behavior are sized for peak demand, even if they spend most of their time idle.
These reserved resources are effectively idle, but you're still paying for them.
The cumulative impact of external and internal fragmentation is massive. Studies estimate that 30% to 50% of cloud infrastructure is idle at any given time, yet still billed. Many reports highlight how over-provisioning is deeply entrenched in cloudnative systems, driven by the unpredictability of workloads and the lack of fine-grained control over infrastructure.
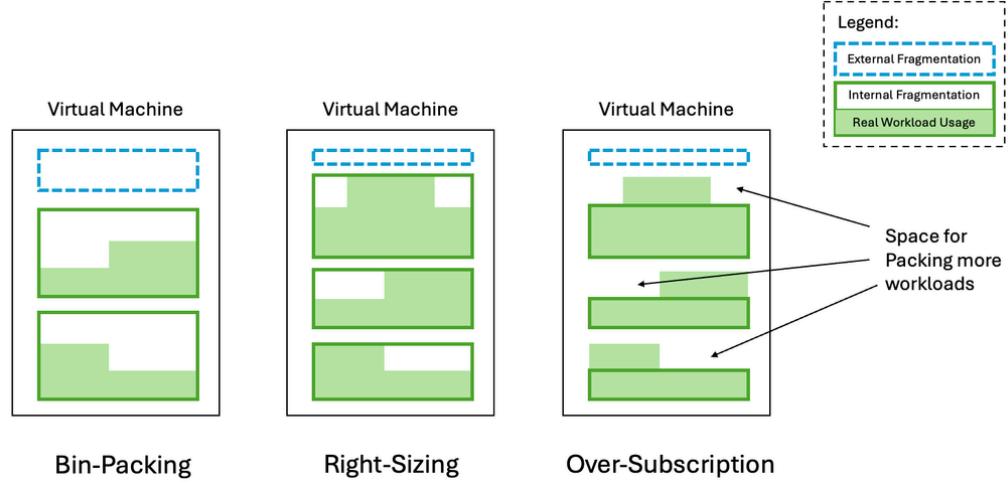
3. Dealing with External Fragmentation: Bin-Packing
One of the most widely used techniques to combat external resource fragmentation is bin-packing. Inspired by the classic algorithmic problem, bin-packing allows scheduling workloads onto infrastructure in a way that tightly fills the available capacity, minimizing unallocated resources left behind on each node or VM.
Modern cloud-native systems implement this strategy in a variety of ways:
- Kubernetes and HPC systems use scheduling heuristics to co-locate workloads based on available capacity.
- Karpenter for Kubernetes and HPC cloud plugins often go further, proactively matching instance types to current workload demand.
- Karpenter even supports workload re-shuffling—relocating workloads across machines to improve packing efficiency as jobs come and go.
Bin-packing helps reduce cost by minimizing external fragmentation and the number of active machines. Despite its popularity, bin-packing has fundamental limitations that become apparent at scale:
1 It doesn't address internal fragmentation
Bin-packing focuses exclusively on how workloads are placed across machines—it assumes the resource requests of those workloads are accurate and efficient. But in reality, workloads are often over-provisioned extensively. Even well-sized workloads experience fluctuating usage over time.
2 Re-shuffling comes at a cost
To keep workloads tightly packed, many systems periodically re-shuffle workloads, migrating them off underutilized nodes so the node can be shut down or repurposed. This technique works well for stateless, short-lived workloads, but it becomes troublesome when dealing with long-running and stateful workloads, such as simulations, analytics pipelines, databases, and other services. These workloads are often disruption-intolerant or carry high restart costs, making eviction unsafe or impractical. As a result, nodes with long-tailed jobs can linger for hours or days, which block consolidation efforts and undermine the entire bin-packing strategy.
4. Reducing Internal Fragmentation: Workload Right-Sizing, Vertical Scaling, and Over-Subscription
If bin-packing tackles resource optimization from the outside, then the natural next step is to optimize from within: making each workload consume only what it truly needs. This is the goal of workload right-sizing and over-subscription, two widely used strategies to reduce internal fragmentation.
4.1 Workload right-sizing and vertical scaling
The most intuitive way to fight internal fragmentation is workload right-sizing. This can be done with prediction: observe historical usage, identify the peak, and size accordingly. Many cloud-native and HPC systems support this with static right-sizing at the time of job submission or deployment, based on historical profiling.
In a perfectly predictable world with workloads that have constant resource usage, right-sizing would eliminate internal fragmentation altogether. However, the real world is messier. In practice, workload resource demands are highly dynamic and often unpredictable:
- A batch job might process drastically different data sets day to day.
- A service may experience fluctuating load based on time of day, user traffic, or external APIs.
- Upstream and downstream services, input size, and concurrency levels all influence a workload's actual resource usage.
This makes right-sizing challenging, and building accurate predictive models for resource requirements is complex and brittle.
To handle dynamic workload requirements, runtime vertical scaling has been explored as an extension to static sizing, such as Vertical Pod Autoscaling VPA in Kubernetes. Although in many systems this kind of runtime adjustment would require a restart of the workload, there are cases where live adjustment can be done without disruptions. For example, Kubernetes now supports inplace vertical scaling of pods.
Workload vertical scaling during runtime can be considered as a mechanism for correcting imperfect right-sizing predictions. However, no matter how you perform right-sizing, the true value can only be realized when you start bin-packing more workloads into the same node. Once workloads are tightly packed, the ability to scale any workload up during a spike is constrained by the leftover resources on the node. In that sense, we're still relying on accurate upfront prediction to avoid contention down the road. So vertical scaling doesn't really solve the problem – it just pushes the problem from job deployment time to runtime.
4.2 Over-subscription
To mitigate over-provisioning without needing perfect prediction, many systems adopt over-subscription. This strategy allows more workloads to be scheduled onto a machine than its theoretical capacity allows, under the assumption that not all workloads will spike at the same time.
Instead of sizing workloads based on their peak, over-subscription uses the resource usage in "normal" situations, which could be defined as the average or a percentile (e.g., 80th percentile), and relies on the diversity of workload patterns to avoid overloading the whole machine.
This can yield much higher node utilization, as long as the assumption holds. While over-subscription helps reduce internal fragmentation, it introduces systemic risk and challenges:
- If multiple workloads spike concurrently, the node can become overloaded. For CPU, this leads to contention and performance degradation. For memory, the stakes are higher: memory overcommitment can trigger out-of-memory OOM) kills, abruptly terminating workloads and causing cascading failures.
- This introduces a multidimensional prediction and optimization problem covering CPU, memory, network, disk, and other resources on the machine. If any one of the dimensions becomes a bottleneck, the other dimensions are hard to optimize.
As a result, over-subscription is often used cautiously, and typically only in environments where workload behavior is well understood, some degradation is acceptable, and safety buffers are applied to deal with sudden spikes.
Ultimately, both right-sizing and over-subscription rely on bin-packing and the ability to predict the unpredictable, with a lack of effective safety mechanism for handling prediction errors. Whether you're using historical data, runtime monitoring, or machine learning models, the challenge remains the same: workloads are dynamic, context-sensitive, and increasingly complicated.
As internal fragmentation becomes harder and harder to handle, organizations are left asking: is there a way to optimize resources without relying on perfect foresight or accepting unacceptable risk? This question leads us to a fundamentally different approach: adaptive infrastructure that responds in real-time. In the next section, we'll introduce Workload Optimizer WO, and explain how it redefines the boundaries of what's possible.
5. Workload Optimizer: Dynamic Node-Level Right-Sizing
If bin-packing helps optimize how workloads are placed, and right-sizing/over-subscription try to tune how much each workload consumes, there's still one piece of the puzzle missing: what if we could make the underlying infrastructure itself more flexible?
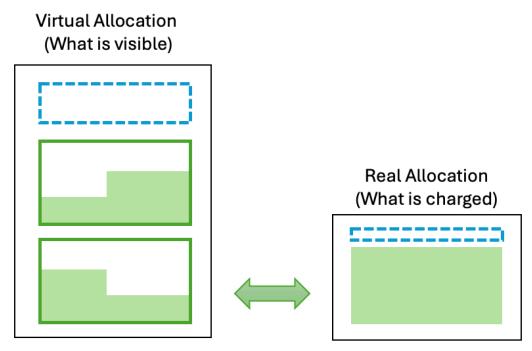
That's the idea behind Workload Optimizer, a system that introduces a completely new capability to cloud computing: virtual machines that can change their size dynamically based on actual usage.
5.1 Rethinking the Role of the Virtual Machine
Traditionally, VMs are static. Once launched, they retain their allocated CPU and memory regardless of actual utilization. If usage drops, you are stuck overpaying. If it spikes, you risk throttling or failure.
WO breaks that mold. It enables dynamic right-sizing at the VM (node) level, so that a VM can scale down when idle, and scale up when needed, all without disruption. This means:
- You no longer need complex algorithms to guess how big a workload might become.
- You no longer need to over-provision "just in case."
- You can reduce both internal and external fragmentation by simply moving VMs to the right size at the right time.
5.2 How Workload Optimizer (WO) Works: Transparent Infrastructure Adaptation
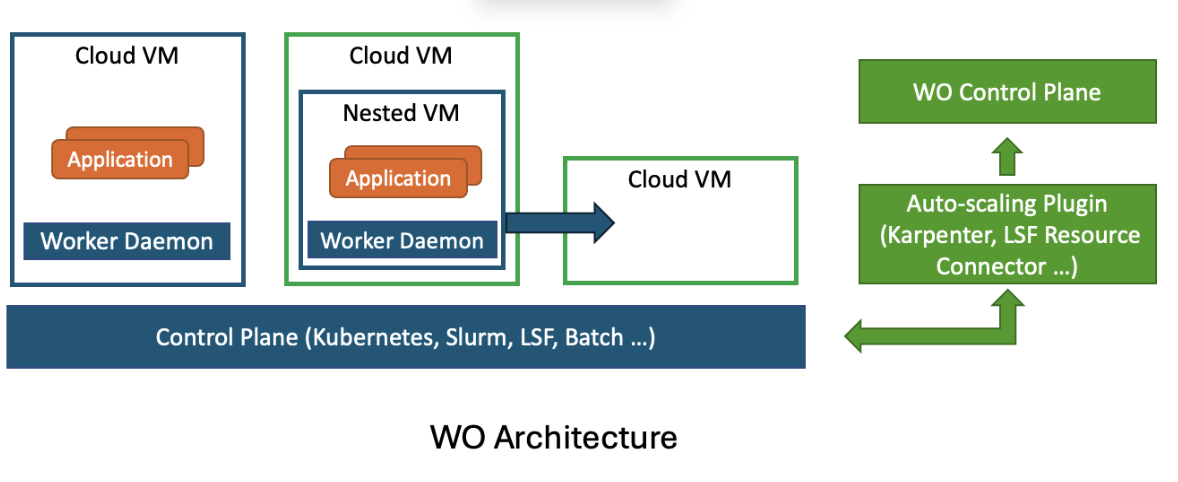
WO introduces a virtualization layer that lives within your cloud VMs, enabling fine-grained control and agility:
Nested Virtualization
Workloads are executed inside nested VMs running on a hypervisor inside cloud VMs. This gives WO the ability to encapsulate a workload's execution environment and control it independently of the underlying infrastructure.
Live Migration Based on Resource Usage
WO continuously monitors resource utilization patterns inside the nested VM. If the workload is consistently underutilizing its allocated resources, WO live migrates the nested VM to a smaller, more cost-efficient cloud VM. If usage rises again, WO scales the VM back up, live and without disruption. If the usage rises so quickly that we run out of critical resources like memory before finishing the migration, WO can hold the memory allocation thread while keeping the OS and other processes running, finish the migration, and resume the execution. No out-of-memory error will be seen by the application.
Multi-dimensional right-sizing
By leveraging the wide variety of cloud VM instance types, WO can scale different resource dimensions independently to match workload needs. For example, on AWS, instance families like C (compute-optimized), R (memory-optimized), and M (generalpurpose) offer distinct CPU-to-memory ratios. This allows WO to scale CPU without affecting memory, or memory without changing CPU. Similarly, network-optimized instances make it possible to increase network I/O bandwidth independently, without altering compute or memory allocations.
Resource Transparency
Perhaps the most important feature: to the workload, the VM capacity doesn't change. Even after being moved to a smaller cloud VM, the nested VM continues to report its original CPU and memory allocation. The application stack sees no change, no disruption, and requires no adaptation.
This resource transparency allows you to safely scale infrastructure behind the scenes, while maintaining consistency for the software running inside.
5.3 Why It Matters
With WO, resource optimization becomes proactive, real-time, and infrastructure-level:
- No more guesswork: There's no need to model future resource needs precisely your infrastructure responds automatically to what's happening now.
- No more massive waste: Idle resources caused by workload inefficiency or poor placement can be largely reclaimed.
- No more disruption: Live migration ensures uninterrupted service, even during resizes.
While Kubernetes is one of the most prominent environments benefiting from WO, the underlying technology is general-purpose. It can be applied to:
- HPC clusters with long-running batch jobs,
- SaaS backends with bursty demand,
- Cloud-native platforms that need elasticity without losing control.
Any system that runs on VMs and suffers from fragmentation, unpredictability, or waste can benefit from the dynamic infrastructure flexibility that WO provides.
6. A Unified Approach to Resource Optimization
As we have seen, modern cloud systems use a variety of strategies to manage resources more effectively. Each approach addresses different aspects of the same core challenge: how do we match infrastructure to dynamic workloads?
Let's recap and compare the techniques discussed in this post:
It's important to emphasize that Workload Optimizer is not a replacement for these other strategies. Instead, it's designed to work alongside them to amplify their effectiveness:
Enhanced Bin-Packing
WO makes bin-packing more powerful by removing internal fragmentation. Nodes can shrink or grow to match the packing density required.
Adaptive Right-Sizing
It enhances right-sizing by offering dynamic infrastructure that adapts to actual usage, removing the penalty for getting the initial prediction wrong.
Safer Over-Subscription
It reduces the risk of over-subscription by enabling reactive scaling when usage spikes unexpectedly.
In essence, WO adds an elastic infrastructure layer to the resource optimization stack, making existing techniques more robust, more flexible, and more cost-effective.
7. Conclusion: Toward Truly Elastic Cloud Infrastructure
Cloud computing promised elasticity, but for most workloads, that elasticity has been limited to scaling out, not up or down.
While engineers have developed clever strategies like bin-packing, workload right-sizing, and over-subscription to get more from their infrastructure, these approaches all share one limitation: they rely on static assumptions about inherently dynamic workloads.
Workload Optimizer (WO) introduces a new dimension: the ability to reshape the infrastructure itself in response to real-time usage. By dynamically resizing virtual machines with live migration and complete resource transparency, WO enables a future where workloads are no longer boxed in by fixed infrastructure boundaries.
And most importantly, WO doesn't ask you to throw out your existing tooling. In a world where cloud cost is rising, workloads are growing more unpredictable, and resource efficiency is becoming mission-critical, WO offers a smarter foundation for adaptive, cost-aware, and disruption-free infrastructure.
Ready to see what truly elastic infrastructure feels like? Reach out to our team for a demo or integration discussion.





